最近,ARM进一步公开了ML Procesor的一些信息。EETimes的文章“Arm Gives Glimpse of AI Core”[1] 和 AnandTech的文章“ARM Details “Project Trillium” Machine Learning Processor Architecture”分别从不同角度进行了介绍,值得我们仔细分析。
ARM公开它的ML Processor是在今年春节前夕,当时公布的信息不多,我也简单做了点分析(AI芯片开年)。
这次ARM公开了更多信息,我们一起来看看。首先是关键的Feature和一些重要信息,2018年中会Release。

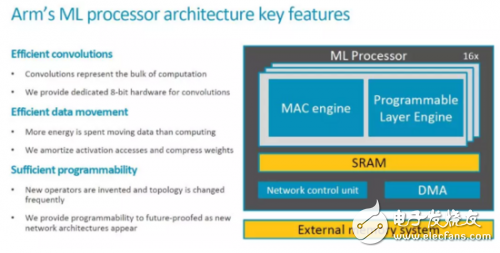
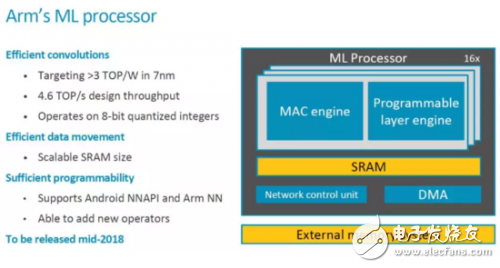
顶层架构
与最初公布的基本框图相比,我们这次看到了更细化的模块框图和连接关系,如下图所示。
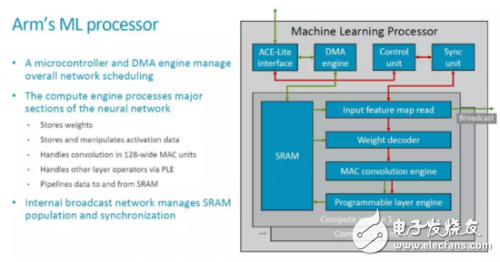
MLP的顶层对外来看是个比较典型的硬件加速器,它有本地的SRAM,通过一个ACE-Lite接口和外部交互数据和主要的控制信息(指令)。另外应该还有一些控制信号,估计在这里略去了(可以参考Nvidia的NVDLA)。
在上图中绿色箭头应该表示的是数据流,红色表示控制流。MLP中的CE共享一套DMA,Control Unit和Sync Unit,它的基本处理流程大概是这样的: 1. 配置Control Unit和DMA Engine;2. DMA Engine从外部(如DDR)读入数据存在本地的SRAM中;3. Input Feature Map Read模块和Weight Read模块分别读入待运算的feature map和weight,处理(比如Weight的解压缩),并发送到MAC ConvoluTIon Engine(后面简称为MCE);4. MCE执行卷积等操作,并把结果传输给Programmable Layer Engine(后面简称为PLE);5. PLE执行其它处理,并将结果写回本地SRAM;6. DMA Engine把结果传输到外部存储空间(如DDR)。
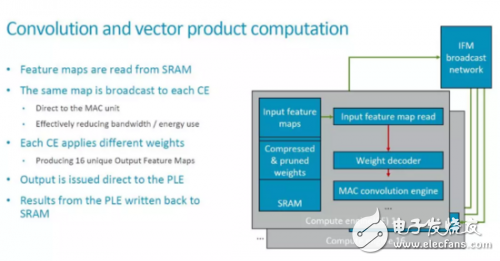
在顶层标出的Broadcast接口,实现在多个Compute Engine(后面简称为CE)之间广播feature map数据的功能。因此,基本的卷积运算模式是,相同的feature map广播到多个CE,不同的CE使用不同的weight来和这些feature map进行运算。
从目前的配置来看,MLP包括16个compute engine,每个有128个MAC,即一共有16x128=2048个MAC,每个cycle可以执行4096个操作。如果要实现ARM所说的4.6TOPS的总的处理能力,则需要时钟周期达到1.12GHz左右。由于这个指标是针对7nm工艺,实现问题不大。
MCE实现高效卷积
在MLP的架构中,MCE和PLE是最重要的功能模块。MCE提供主要的运算能力(处理90%的运算),应该也是MLP中面积和功耗最大的部分。因此,MCE设计优化的一个主要目标就是实现高效的卷积操作。具体来讲,MLP的设计主要考虑了以下一些方法,这些方法大部分我们之前也都讨论过。
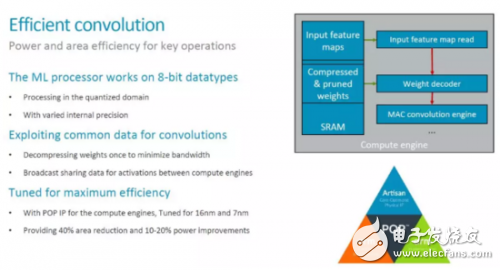
一个比较有趣的点是上面提到的“varied internal precision”。目前还不太清楚其具体的含义。不过对应用来说看到的应该是固定的8bit数据类型。至于对低精度Inference的支持,[1]中提供的信息是, “The team is tracking research on data types down to 1-bit precision, including a novel 8-bit proposal from Microsoft. So far, the alternaTIves lack support in tools to make them commercially viable, said Laudick.” 因此在第一版的MLP中,应该也不会看到低精度或者Bit-serial MAC了(参考AI芯片开年中对ISSCC2018出现的Bit-serial Processing的介绍)。
此外,数据的压缩和对工艺的优化也是提高整体效率的主要手段。特别是工艺的优化,结合ARM的工艺库,应该有比较好的效果,这也是ARM有优势的地方。
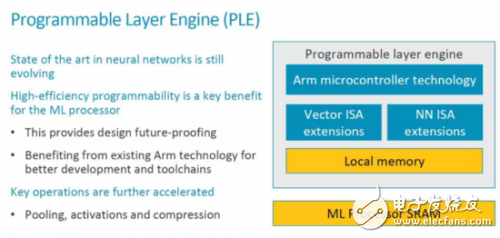
PLE实现高效的可编程性
如下图所示,PLE的结构基本是在一个ARM MCU基础上扩展了Vector处理和NN处理的指令。在讨论可编程性的时候,其出发点主要是NN算法和架构目前还在不断演进。
我们前面已经分析了整个MLP的基本工作流程,MCE在完成了运算之后把结果传输给PLE。从这里可以看出,MCE应该是把结果发送到Vector Register File(VRF),然后产生中断通知CPU。之后,CPU启动Vector Engine对数据进行处理。具体如下图所示。
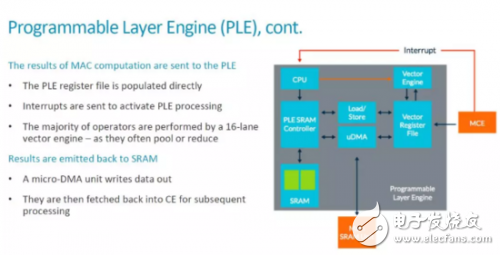
对于做专用处理器的同学来说,这种scalar CPU+vector engine的架构并不陌生。这里,本地SRAM,VRF和PLE之外的Maing SRAM Unit(CE中的SRAM)之间有Load/Store单元和uDMA实现数据的传输,数据流也是比较灵活的。综合来看, 在MLP中,每个CE中都有一个PLE和MCE配合,即每个MCE(128个MAC)就对应一个可编程架构。 因此,ARM MLP的可编程性和灵活性是要远高于Google TPU1和Nvidia的NVDLA的。当然,灵活性也意味着更多额外的开销,如[1]中指出的,“The programmable layer engine (PLE) on each slice of the core offers “ just enough programmability to perform [neural-net] manipulaTIons ””。High-efficient Programmability是MLP的一个主要卖点之一,而ARM的“just enough”是否真是最合适的选择,还有待进一步观察。


