Observer协处理器通常在一个特定的事件(诸如Get或Put)之前或之后发生,相当于RDBMS中的触发器。Endpoint协处理器则类似于RDBMS中的存储过程,因为它可以让你在RegionServer上对数据执行自定义计算,而不是在客户端上执行计算。
1 协处理器简介
如果要统计HBase中的数据,比如统计某个字段的最大值、统计满足某种条件的记录数、统计各种记录的特点并按照记录特点分类等等,常规的做法是把HBase中整个表的数据Scan出来,或者加一个Filter,进行一些初步的过滤,然后在客户端进行统计处理。但是这么做会有很大的副作用,比如占用大量的网络带宽(大数据量尤为明显),RPC的压力也是不容小觑的。
HBase作为列式数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执行求和、计数、排序等操作。比如,在旧版本的(《0.92)HBase中,统计数据表的总行数,需要使用Counter方法,执行一次MapReduce Job才能得到。虽然HBase在数据存储层中集成了MapReduce,能够有效进行数据表的分布式计算,然而在很多情况下,做一些简单的相加或者聚合计算的时候,如果直接将计算过程放置在server端,能够减少网络开销,从而获得很好的性能提升。于是,HBase在0.92之后引入了协处理器(coprocessors),实现了一些激动人心的新特性:能够轻易建立二次索引、复杂过滤器以及访问控制等。
简单理解来说,协处理器是HBase让用户的部分逻辑在数据存放端即HBase服务端进行计算的机制,它允许用户在HBase服务端运行自己的代码。
2 协处理器的分类
协处理器分为两种类型:系统协处理器可以全局导入Region Server上的所有数据表,表协处理器是用户可以指定一张表使用的协处理器。协处理器框架为了更好支持其行为的灵活性,提供了两个不同方面的插件。一个是观察者(Observer),类似于关系数据库的触发器。另一个是终端(Endpoint),动态的终端有点像存储过程。
Observer的设计意图是允许用户通过插入代码来重载协处理器框架的upcall方法,而具体的事件触发的callback方法由HBase的核心代码来执行。协处理器框架处理所有的callback调用细节,协处理器自身只需要插入添加或者改变的功能。
Endpoint是动态RPC插件的接口,它的实现代码被安装在服务器端,从而能够通过HBase RPC唤醒。客户端类库提供了非常方便的方法来调用这些动态接口,它们可以在任意时候调用一个终端,它们的实现代码会被目标Region远程执行,结果会返回到终端。用户可以结合使用这些强大的插件接口,为HBase添加全新的特性。
3 Protocol Buffer的使用
由于下面的Endpoint编码示例使用了Google公司的混合语言数据标准Protocol Buffer,所以首先了解一下这个常用于RPC系统的工具。
3.1 ProtocolBuffer介绍
Protocol Buffer是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,很适合做数据存储或RPC数据交换格式。它可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。目前提供了C++、Java、Python三种语言的 API。
为什么要使用Protocol Buffer呢?先看一个在实际开发中经常会遇到的系统场景:我们的客户端程序是使用Java开发的,可能运行自不同的平台,如Linux、Windows或者是Android,而我们的服务器程序通常是基于Linux平台并使用C++开发完成的。在这两种程序之间进行数据通讯时存在多种方式用于设计消息格式,如:
1、直接传递C/C++语言中字节对齐的结构体数据,只要结构体的声明为定长格式,那么该方式对于C/C++程序而言就非常方便了,仅需将接收到的数据按照结构体类型强行转换即可。事实上对于变长结构体也不会非常麻烦。在发送数据时,也只需定义一个结构体变量并设置各个成员变量的值之后,再以char*的方式将该二进制数据发送到远端。反之,该方式对于Java开发者而言就会非常繁琐,首先需要将接收到的数据存于ByteBuffer之中,再根据约定的字节序逐个读取每个字段,并将读取后的值再赋值给另外一个值对象中的域变量,以便于程序中其他代码逻辑的编写。对于该类型程序而言,联调的基准是必须客户端和服务器双方均完成了消息报文构建程序的编写后才能展开,而该设计方式将会直接导致Java程序开发的进度过慢。即便是Debug阶段,也会经常遇到Java程序中出现各种域字段拼接的小错误。
2、使用SOAP协议(WebService)作为消息报文的格式载体,由该方式生成的报文是基于文本格式的,同时还存在大量的XML描述信息,因此将会大大增加网络IO的负担。又由于XML解析的复杂性,这也会大幅降低报文解析的性能。总之,使用该设计方式将会使系统的整体运行性能明显下降。
对于以上两种方式所产生的问题,Protocol Buffer均可以很好的解决,不仅如此,Protocol Buffer还有一个非常重要的优点就是可以保证同一消息报文新旧版本之间的兼容性。
3.2 安装Protocol Buffer
// 在https://developers.google.com/protocol-buffers/docs/downloads下载protobuf-2.6.1.tar.gz后解压至指定目录
$ tar -xvf protobuf-2.6.1.tar.gz -C app/
// 删除压缩包
$ rm protobuf-2.6.1.tar.gz
// 安装c++编译器相关包
$ sudo apt-get install g++
// 编译安装protobuf
$ cd app/protobuf-2.6.1/
$ 。/configure
$ make
$ make check
$ sudo make install
// 添加到lib
$ vim ~/.bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
$ source ~/.bashrc
// 验证是否安装成功
$ protoc --version
3.3 编写proto文件
首先需要编写一个 proto 文件,定义程序中需要处理的结构化数据。proto 文件非常类似java或者C语言的数据定义。如下代码给出了示例中定义RPC接口的 endpoint.proto文件内容:
[plain] view plain copy// 定义常用选项
opTIon java_package = “com.hbase.demo.endpoint”; //指定生成Java代码的包名
opTIon java_outer_classname = “Sum”; //指定生成Java代码的外部类名称
opTIon java_generic_services = true; //基于服务定义产生抽象服务代码
opTIon optimize_for = SPEED; //指定优化级别
// 定义请求包
message SumRequest {
required string family = 1; //列族
required string column = 2; //列名
}
// 定义回复包
message SumResponse {
required int64 sum = 1 [default = 0]; //求和结果
}
// 定义RPC服务
service SumService {
//获取求和结果
rpc getSum(SumRequest)
returns (SumResponse);
}
3.4 编译proto文件
// 将proto文件编译生成java代码
$ protoc endpoint.proto --java_out=。/
// 生成的文件Sum.java如下图所示:

4 Endpoint编码示例
业务逻辑如求和、排序等功能放在服务端,在服务端完成计算后将结果发送给客户端,可以减少数据的传输量。下面的示例将在HBase的服务端生成一个RPC服务,即在服务端对指定表的指定列值进行求和计算,并将计算结果返回给客户端。客户端调用该RPC服务,获取响应结果后输出。
4.1 服务端代码
首先,将通过Protocol Buffer生成的RPC接口文件Sum.java导入项目,然后在项目中新建类SumEndPoint编写服务端代码:
[java] view plain copypackage com.hbase.demo.endpoint;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.Coprocessor;
import org.apache.hadoop.hbase.CoprocessorEnvironment;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.coprocessor.CoprocessorException;
import org.apache.hadoop.hbase.coprocessor.CoprocessorService;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.protobuf.ResponseConverter;
import org.apache.hadoop.hbase.regionserver.InternalScanner;
import org.apache.hadoop.hbase.util.Bytes;
import com.google.protobuf.RpcCallback;
import com.google.protobuf.RpcController;
import com.google.protobuf.Service;
import com.hbase.demo.endpoint.Sum.SumRequest;
import com.hbase.demo.endpoint.Sum.SumResponse;
import com.hbase.demo.endpoint.Sum.SumService;
/**
* @author developer
* 说明:hbase协处理器endpooint的服务端代码
* 功能:继承通过protocol buffer生成的rpc接口,在服务端获取指定列的数据后进行求和操作,最后将结果返回客户端
*/
public class SumEndPoint extends SumService implements Coprocessor,CoprocessorService {
private RegionCoprocessorEnvironment env; // 定义环境
@Override
public Service getService() {
return this;
}
@Override
public void getSum(RpcController controller, SumRequest request, RpcCallback《SumResponse》 done) {
// 定义变量
SumResponse response = null;
InternalScanner scanner = null;
// 设置扫描对象
Scan scan = new Scan();
scan.addFamily(Bytes.toBytes(request.getFamily()));
scan.addColumn(Bytes.toBytes(request.getFamily()), Bytes.toBytes(request.getColumn()));
// 扫描每个region,取值后求和
try {
scanner = env.getRegion().getScanner(scan);
List《Cell》 results = new ArrayList《Cell》();
boolean hasMore = false;
Long sum = 0L;
do {
hasMore = scanner.next(results);
for (Cell cell : results) {
sum += Long.parseLong(new String(CellUtil.cloneValue(cell)));
}
results.clear();
} while (hasMore);
// 设置返回结果
response = SumResponse.newBuilder().setSum(sum).build();
} catch (IOException e) {
ResponseConverter.setControllerException(controller, e);
} finally {
if (scanner != null) {
try {
scanner.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 将rpc结果返回给客户端
done.run(response);
}
// 协处理器初始化时调用的方法
@Override
public void start(CoprocessorEnvironment env) throws IOException {
if (env instanceof RegionCoprocessorEnvironment) {
this.env = (RegionCoprocessorEnvironment)env;
} else {
throw new CoprocessorException(“no load region”);
}
}
// 协处理器结束时调用的方法
@Override
public void stop(CoprocessorEnvironment env) throws IOException {
}
}
4.2 客户端代码
在项目中新建类SumClient作为调用RPC服务的客户端测试程序,代码如下:
[java] view plain copypackage com.hbase.demo.endpoint;
import java.io.IOException;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.coprocessor.Batch;
import org.apache.hadoop.hbase.ipc.BlockingRpcCallback;
import com.google.protobuf.ServiceException;
import com.hbase.demo.endpoint.Sum.SumRequest;
import com.hbase.demo.endpoint.Sum.SumResponse;
import com.hbase.demo.endpoint.Sum.SumService;
/**
* @author developer
* 说明:hbase协处理器endpooint的客户端代码
* 功能:从服务端获取对hbase表指定列的数据的求和结果
*/
public class SumClient {
public static void main(String[] args) throws ServiceException, Throwable {
long sum = 0L;
// 配置HBse
Configuration conf = HBaseConfiguration.create();
conf.set(“hbase.zookeeper.quorum”, “localhost”);
conf.set(“hbase.zookeeper.property.clientPort”, “2222”);
// 建立一个数据库的连接
Connection conn = ConnectionFactory.createConnection(conf);
// 获取表
HTable table = (HTable) conn.getTable(TableName.valueOf(“sum_table”));
// 设置请求对象
final SumRequest request = SumRequest.newBuilder().setFamily(“info”).setColumn(“score”).build();
// 获得返回值
Map《byte[], Long》 result = table.coprocessorService(SumService.class, null, null,
new Batch.Call《SumService, Long》() {
@Override
public Long call(SumService service) throws IOException {
BlockingRpcCallback《SumResponse》 rpcCallback = new BlockingRpcCallback《SumResponse》();
service.getSum(null, request, rpcCallback);
SumResponse response = (SumResponse) rpcCallback.get();
return response.hasSum() ? response.getSum() : 0L;
}
});
// 将返回值进行迭代相加
for (Long v : result.values()) {
sum += v;
}
// 结果输出
System.out.println(“sum: ” + sum);
// 关闭资源
table.close();
conn.close();
}
}
4.3 加载Endpoint
// 将Sum类和SumEndPoint类打包后上传到HDFS
$ hadoopfs -put endpoint_sum.jar /input
// 修改hbase配置文件,添加配置
$ vimapp/hbase-1.2.0-cdh5.7.1/conf/hbase-site.xml
[html] view plain copy《property》
《name》hbase.table.sanity.checks《/name》
《value》false《/value》
《/property》
// 重启hbase
$stop-hbase.sh
$start-hbase.sh
// 启动hbase shell
$hbase shell
// 创建表sum_table
》 create‘sum_table’,‘info’
// 插入测试数据
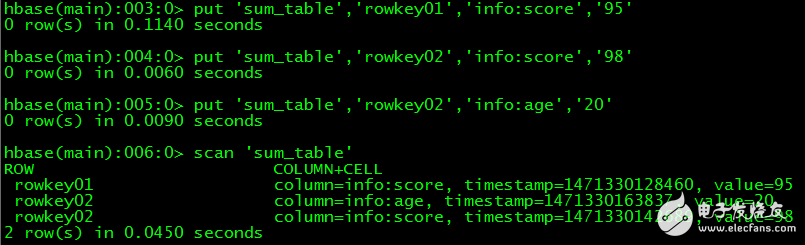
》 put‘sum_table’,‘rowkey01’,‘info:score’,‘95’
》 put‘sum_table’,‘rowkey02’,‘info:score’,‘98’
》 put‘sum_table’,‘rowkey02’,‘info:age’,‘20’
// 查看数据
》 scan‘sum_table’
// 加载协处理器
》disable ‘sum_table’
》 alter‘sum_table’,METHOD =》‘table_att’,‘coprocessor’ =》‘hdfs://localhost:9000/input/endpoint_sum.jar|com.hbase.demo.endpoint.SumEndPoint|100’
》enable ‘sum_table’

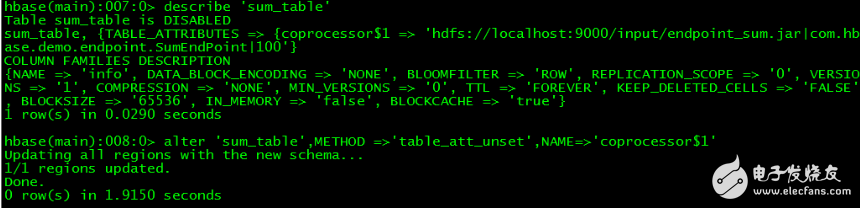
// 如果要卸载协处理器,可以先查看表中协处理器名,然后通过命令卸载
》disable ‘sum_table’
》 describe‘sum_table’
》 alter‘sum_table’,METHOD =》‘table_att_unset’,NAME=》‘coprocessor$1’
》 enable‘sum_table’
4.4 测试
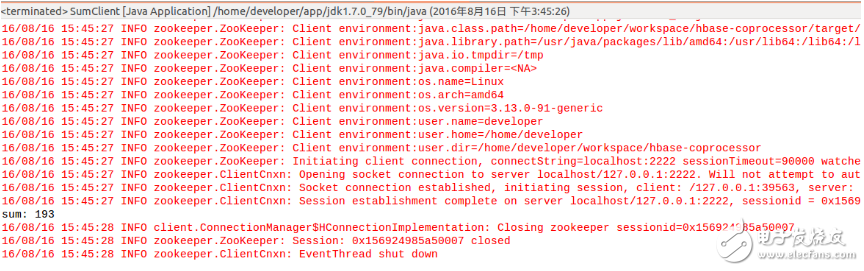
在eclipse中运行客户端程序SumClient,输出结果为193,正好符合预期,如下图所示:
5 Observer编码示例
一般来说,对数据库建立索引,往往需要单独的数据结构来存储索引的数据。在hbase表中,除了使用rowkey索引数据外,还可以另外建立一张索引表,查询时先查询索引表,然后用查询结果查询数据表。下面这个示例演示如何使用Observer协处理器生成HBase表的二级索引:将数据表ob_table中列info:name的值作为索引表index_ob_table的rowkey,将数据表ob_table中列info:score的值作为索引表index_ob_table中列info:score的值建立二级索引,当用户向数据表中插入数据时,索引表将自动插入二级索引,从而为查询业务数据提供了便利。
5.1 代码
在项目中新建类PutObserver作为Observer协处理器应用逻辑类,代码如下:
[java] view plain copypackage com.hbase.demo.observer;
import java.io.IOException;
import java.util.List;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Durability;
import org.apache.hadoop.hbase.client.HTableInterface;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.regionserver.wal.WALEdit;
import org.apache.hadoop.hbase.util.Bytes;
/**
* @author developer
* 说明:hbase协处理器observer的应用逻辑代码
* 功能:在应用了该observer的hbase表中,所有的put操作,都会将每行数据的info:name列值作为rowkey、info:score列值作为value
* 写入另一张二级索引表index_ob_table,可以提高对于特定字段的查询效率
*/
@SuppressWarnings(“deprecation”)
public class PutObserver extends BaseRegionObserver{
@Override
public void postPut(ObserverContext《RegionCoprocessorEnvironment》 e,
Put put, WALEdit edit, Durability durability) throws IOException {
// 获取二级索引表
HTableInterface table = e.getEnvironment().getTable(TableName.valueOf(“index_ob_table”));
// 获取值
List《Cell》 cellList1 = put.get(Bytes.toBytes(“info”), Bytes.toBytes(“name”));
List《Cell》 cellList2 = put.get(Bytes.toBytes(“info”), Bytes.toBytes(“score”));
// 将数据插入二级索引表
for (Cell cell1 : cellList1) {
// 列info:name的值作为二级索引表的rowkey
Put indexPut = new Put(CellUtil.cloneValue(cell1));
for (Cell cell2 : cellList2) {
// 列info:score的值作为二级索引表中列info:score的值
indexPut.add(Bytes.toBytes(“info”), Bytes.toBytes(“score”), CellUtil.cloneValue(cell2));
}
// 数据插入二级索引表
table.put(indexPut);
}
// 关闭资源
table.close();
}
}
5.2 加载Observer
// 将PutObserver类打包后上传到HDFS
$ hadoopfs -put ovserver_put.jar /input
// 启动hbase shell
$hbase shell
// 创建数据表ob_table
》 create‘ob_table’,‘info’
// 创建二级索引表ob_table
》 create‘index_ob_table’,‘info’
// 加载协处理器
》disable ‘ob_table’
》 alter‘ob_table’,METHOD =》‘table_att’,‘coprocessor’ =》‘hdfs://localhost:9000/input/observer_put.jar|com.hbase.demo.observer.PutObserver|100’
》 enable‘ob_table’
// 查看数据表ob_table
》 describe‘ob_table’

5.3 测试
// 在eclipse项目中编写一个客户端,向数据表ob_table中插入测试数据
[java] view plain copypackage com.hbase.demo.observer;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
public class Test {
public static void main(String[] args) throws IOException {
// 配置HBse
Configuration conf = HBaseConfiguration.create();
conf.set(“hbase.zookeeper.quorum”, “localhost”);
conf.set(“hbase.zookeeper.property.clientPort”, “2222”);
// 建立一个数据库的连接
Connection conn = ConnectionFactory.createConnection(conf);
// 获取表
HTable table = (HTable) conn.getTable(TableName.valueOf(“ob_table”));
// 插入测试数据
Put put = new Put(Bytes.toBytes(“rowkey01”));
put.addColumn(Bytes.toBytes(“info”), Bytes.toBytes(“name”), Bytes.toBytes(“carl”));
put.addColumn(Bytes.toBytes(“info”), Bytes.toBytes(“score”), Bytes.toBytes(“92”));
table.put(put);
// 关闭资源
table.close();
conn.close();
}
}
// 插入数据后,在hbase shell中查看数据表ob_table中的数据
$hbase shell
》 scan‘ob_table’

//在hbase shell中查看二级索引表index_ob_table中的数据
》 scan‘index_ob_table’



