随着更快的图形处理单元(GPU)能够提供明显更高的计算能力,存储设备和GPU存储器之间的数据路径瓶颈已经无法实现最佳应用程序性能。NVIDIA的Magnum IO GPUDirect存储解决方案通过在存储设备和GPU存储器之间实现直接路径,可以极大地帮助解决该问题。然而,同等重要的是要使用容错系统来优化其已经非常出色的能力,从而确保在发生灾难性故障时备份关键数据。该解决方案通过PCIe®结构连接逻辑RAID卷,在PCIe 4.0规范下,这可以将数据速率提高到26 GB/s。为了解如何实现这些优势,首先需要检查该解决方案的关键组件及其如何协同工作来提供结果。
Magnum IO GPUDirect存储
Magnum IO GPUDirect存储解决方案的关键优势是其能够消除主要性能瓶颈之一,方法是不使用CPU中的系统存储器将数据从存储设备加载到GPU中进行处理。通常将数据移动到主机存储器并传送到GPU,这依赖于CPU系统存储器中的回弹缓冲区,在数据传送到GPU之前,会在其中创建数据的多个副本。但是,通过这种路径移动大量数据会产生延迟时间,降低GPU性能,并在主机中占用许多CPU周期。借助Magnum IO GPUDirect存储解决方案,无需访问CPU并避免了回弹缓冲区效率低下(图1)。

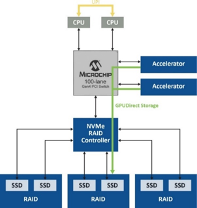
图1. Magnum IO GPUDirect存储解决方案无需访问CPU,避免了从数据路径回弹缓冲
性能直接随着传送数据量的增加而提高,传送数据量则随着人工智能(AI)、机器学习(ML)、深度学习(DL)和其他数据密集型应用所需的大型分布式数据集呈指数级增长。当数据在本地存储或远程存储时,可以实现这些优势,从而允许以比CPU存储器中的页面缓存更快的速度访问数拍字节的远程存储。
优化RAID性能
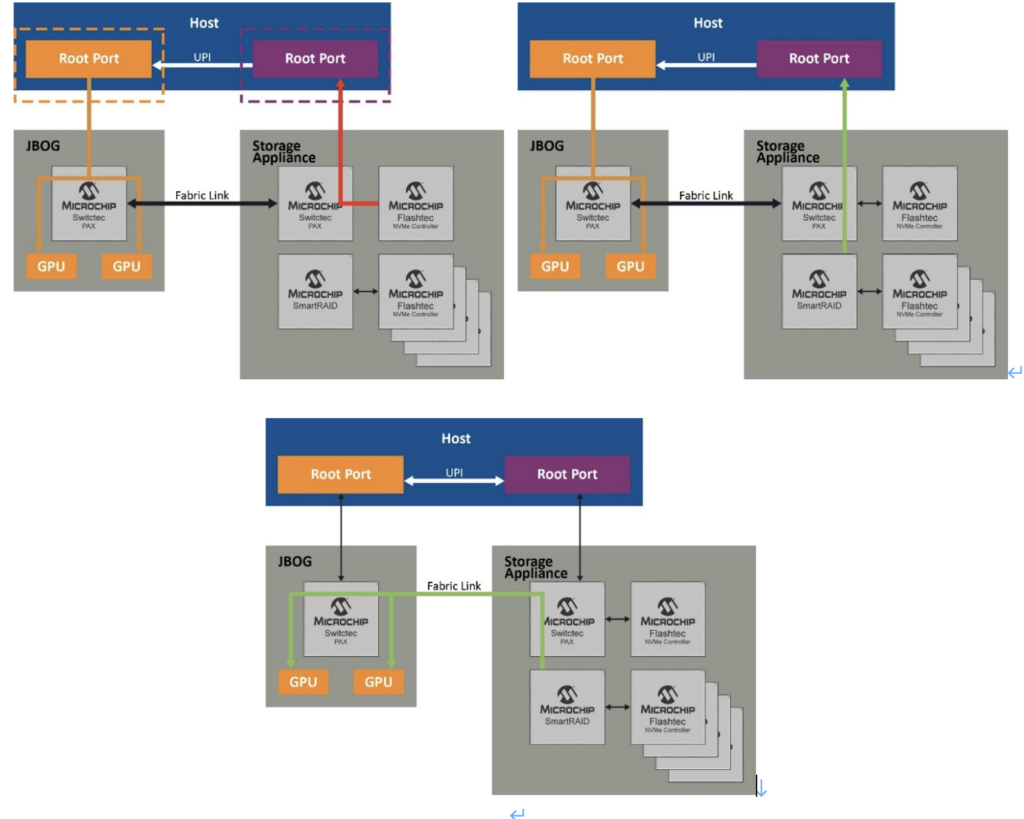
该解决方案中的下一个元素是包括RAID功能,用于保持数据冗余和容错能力。虽然软件RAID可以提供数据冗余,但底层软件RAID引擎仍然使用精简指令集计算机(RISC)架构进行操作,例如奇偶校验计算。当比较高级RAID级别(例如RAID 5和RAID 6)的写I/O延迟时间时,硬件RAID仍然比软件RAID快得多,因为提供了专用处理器来执行这些操作和回写高速缓存。在流传输应用中,软件RIAD的长期RIAD响应时间会导致数据堆积在高速缓存中。硬件RAID解决方案不存在缓存数据堆积问题,并且具有专门的备用电池,可以防止出现灾难性系统掉电时数据丢失的情况。
标准硬件RAID虽然减轻了主机的奇偶校验管理负担,但大量数据仍需经过RAID控制器才能发送到NVMe®驱动器,导致数据路径更加复杂。针对此问题的解决方案是NVMe优化的硬件RAID,该解决方案提供了简化的数据路径,无需经过固件或RAID片上控制器即可传送数据。它还允许维护基于硬件的保护和加密服务。
混合PCIe结构
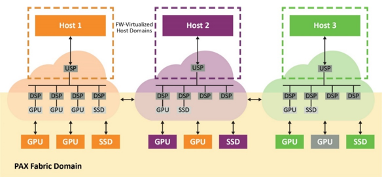
PCIe Gen 4现在是存储子系统内的基本系统互连接口,但标准PCIe交换网具有与前几代相同的基于树的基本层级。这意味着,主机间通信需要非透明桥接(NTB)来实现跨分区通信,这使其变得复杂,特别是在多主机多交换网配置中。Microchip的PAX PCIe高级结构交换网等解决方案能够克服这些限制,因为它们支持冗余路径和循环,而这是使用传统PCIe无法实现的。
结构交换网具有两个独立的域,主机虚拟域(专用于每个物理主机)和结构域(包含所有端点和结构链路)。来自主机域的事务会在结构域中转换为ID和地址,反之,结构域中通信的非分层路由也是如此。这样,系统中的所有主机便可共享连接到交换网和端点的结构链路。
在嵌入式CPU上运行的结构固件通过可配置的下行端口数虚拟化符合PCIe标准的交换网。因此,交换网将始终显示为具有直连端点的标准单层PCIe设备,而与这些端点在结构中的位置无关。由于结构交换网会拦截来自主机的所有配置平面通信(包括PCIe枚举过程)并选择最佳路径,因此它可以实现这一点。这样,GPU等端点便可绑定到域中的任何主机(图2)。