0 引言
当前信号处理领域内阵列信号处理技术正在迅速发展,各种新的算法及新的处理技术不断出现,要求信号处理系统具有快速适应各种新算法和新技术的能力,采用传统的基于专用硬件的设计方法所开发出来的信号处理系统无法满足这样的要求。开发具有通用性的计算平台,尽可能通过软件来实现信号处理功能,成为信号处理的新趋势,“软件雷达”、“软件无线电”等概念都是基于这一思想。
通过灵活的软件编程来适应算法的变化,通过简单的硬件扩展来适应规模的变化,使系统的灵活性大大提高,研制周期、费用大为减少。要支持这种设计思路,必须研制出组成通用计算平台的信号处理模块,该模块既能满足系统实时处理需求,又具备通用性、可扩展性。
1 系统结构
随着微电子技术的突飞猛进,处理器的速度不断得以提高,但实际应用对于计算能力的需求还是远远超出了单个处理器可以提供的范围,采用并行处理技术构成多处理器系统满足需要较强计算能力的应用是一种行之有效的技术途径。
并行处理的目的是通过采用多个处理单元同时对任务进行处理,加速整个计算的过程,从而减少任务的执行时间。整个任务可分解成一些小的任务,分别分配给并行处理系统中各个处理单元执行。一般而言,这些并行执行的任务都不能完全独立执行,一个任务中的计算可能需要用到另一个任务中的数据,各处理单元之间存在进行数据交换的要求。因为交换数据而必须等待的时间,反映了处理单元之间的同步开销。因此不难看出,并行处理额外增加了数据通信和同步等待等开销。
为使任务执行时间减少增加处理单元个数成为首要手段,同时要将任务进行更细粒度的划分以增加任务的并行度,但在增加处理单元和任务细粒度化的同时将带来总通信量的增加,再加上同步时间和任务分配不均所造成的空等待时间开销,增加处理单元的个数对增加系统处理能力得不偿失。这使得在设计并行处理系统时必须着重考虑以下两个方面:处理单元性能的提高以及处理单元间通信技术的改进。
1.1 处理单元的选择
在通信、语音、图像处理中信号的动态范围有限,一般采用定点运算就可以满足要求,雷达、声纳信号需要较大的数据动态范围和数据精度,若按定点处理会发生数据上溢出或下溢出,严重时处理将无法进行,如果使用移位定标或用定点模拟浮点运算,程序的执行速度将大大降低,为增强计算平台的适用性,该通用信号处理平台使用浮点处理器。
同样的任务量,用高性能的处理单元构成的“小”规模系统,其效率要高于用较低性能的处理单元构成的“大”规模系统。并行处理单元的性能相当重要,它不仅包括运算速度,还包括存储器带宽、数据通信速度等,美国TI公司的TMS320C6000系列DSP是业界最高性能的通用可编程DSP,TMS320C6701又是该系列中性能较高的浮点处理器。该款DSP完全满足设计的通用计算平台对信号处理单元性能的要求,因此选择TMS320C6701作为信号处理模块的处理单元。
1.2 通信网络的设计
阵列信号处理必然是多个信号处理单元并行工作,子任务分配在并行处理系统的各个处理单元中,子任务间数据通信速度和同步时间等不仅取决于处理单元本身的通信速度,还取决于连接处理单元的通信互连网络,通信链路丰富的复杂网络往往能提供较高的数据通信速度,然而其设计和维护的难度要高得多。针对不同的实际应用,采用不同形式的通信网络,可以降低通信网络的复杂度。
在互连结构设计中,把整个并行信号处理系统的互连结构分为两级:系统级互连结构、模块级互连结构。
系统级互连结构主要用于模块间的通信,该设计中系统级的控制网络和信号处理网络分别采用RaceWay及VME实现。模块级互连结构主要指信号处理模块内的网络结构。信号处理模块系统结构如图1所示。

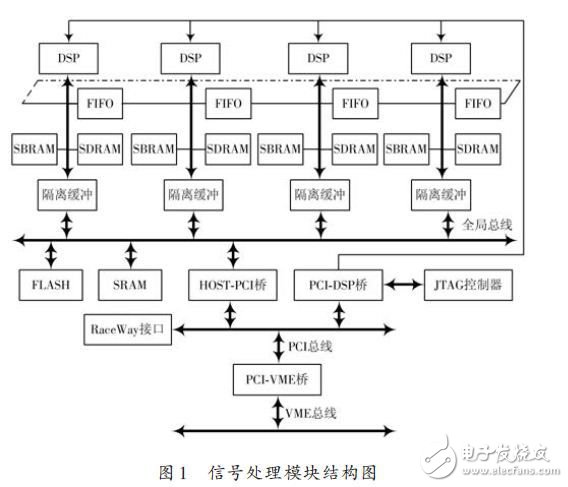
信号处理模块内包含4个DSP,可提供4GFLOPS的峰值处理能力。模块内采用共享总线互连结构。一般情况下,程序代码和运算数据应存放于各 DSP的片内RAM或局部存储器中,这样可以减少共享存储器访问次数,减少总线争用,缩短存储访问延时。共享存储器通常用来支持模块内4个DSP之间交换数据,以及用来支持在模块之间交换数据。
为了减少模块内各个DSP争用总线带来的时延,提高DSP之间的通信能力,相邻的DSP之间还通过双向的FIFO连接,构成FIFO环。这种结构十分适合流水处理的应用,最大限度地减小了数据移动的开销,提高了处理器间的通信速度。
流水处理以其简单高效而被广泛采用,但因为它只利用了任务时间上的并行性,而忽视了空间上的并行性,所以并行度不高,加速比受到限制。当流水线中某一段任务负载量大于其他段时,就会形成处理瓶颈而降低系统效率。因此,流水线往往和并发操作结合起来,即在流水线处理的基础上,部分的利用空间并行性,称为局部并行全局串行网络。与之对应的是全局并行局部串行网络,即先利用空间并行性再利用时间并行性,设计出并行工作的多条流水线。
该并行信号处理系统的信号处理模块所采用的互连形式--共享总线和FIFO环的结构,能够很好地适应流水处理的各种变形。