语音通信从最初的只有有线通信变成后来的有线通信与无线通信(移动通信)的竞争,当移动语音通信价格下来后有线语音通信明显处于逆势。如今移动语音通信的竞争对手是OTT(On The Top)语音,OTT语音是互联网厂商提供的服务,一般免费,如微信语音。目前语音通信技术上就分成了两大阵营:传统通信阵营和互联网阵营,互相竞争,推动着语音通信技术的发展。具体到编解码器上互联网阵营提出了涵盖语音和音乐的音频编解码器OPUS(OPUS是由非盈利的Xiph.org 基金会、Skype 和Mozilla 等共同主导开发的,全频段(8kHZ到48kHZ),支持语音和音乐(语音用SILK, 音乐用CELT),已被IETF接纳成为网络上的声音编解码标准(RFC6716)),绝大多数OTT语音的APP都支持,有一统互联网阵营的趋势。移动通信标准组织3GPP为了应对互联网阵营的竞争,也提出了涵盖语音和音乐的音频编解码器EVS(Enhanced Voice Service)。我曾经给我做的手机平台上成功的加上了EVS,并且通过了中国移动的实网环境下的测试。下面就讲讲这个codec以及用好要做的工作。
3GPP在2014年9月将EVS编解码器标准化,由3GPP R12版本定义,主要适用于VoLTE, 但也同时适用于VoWiFi和固定网络电话VoIP。EVS编解码器由运营商、终端设备、基础设施和芯片提供商以及语音与音频编码方面的专家联合开发,其中包括爱立信、Fraunhofer集成电路研究所、华为技术有限公司、诺基亚公司、日本电信电话公司(NTT)、日本NTT DOCOMO公司、法国电信(ORANGE)、日本松下公司、高通公司、三星电子公司、VoiceAge公司及中兴通讯股份有限公司等。它是3GPP迄今为止性能和质量最好的语音频编码器,它是全频段(8kHZ到48kHZ),可以在5.9kbps至128kbps的码率范围内工作,不仅对于语音和音乐信号都能够提供非常高的音频质量,而且还具有很强的抗丢帧和抗延时抖动的能力,可以为用户带来全新的体验。
下图是3GPP EVS相关的SPEC,从TS26.441到TS26.451。


我已将关键的几个用红框标出,其中TS26.441是总览,TS26.442是用C语言写的定点实现(reference code),这也是后面用好EVS工作中的重中之重。TS26.444是测试序列,优化reference code过程中几乎每天都要保存一个优化的版本,每天都要用测试序列跑一跑优化的版本,如发现不一样了,说明优化的有问题,要退到上一个版本,并检查出哪一步优化出问题了。TS26.445是EVS算法的具体描述,近700页,说实话看的头疼,如果不是做算法的,算法部分看个大概就可以了,但是对特性描述相关的一定要细看。
EVS对语音信号和音乐信号采用不同的编码器。语音编码器是改进型代数码激励线性预测(ACELP),还采用了适合不同语音类别的线性预测模式。对于音乐信号编码,则采用频域(MDCT)编码方式, 并特别关注低延迟/低比特率情况下的频域编码效率,从而在语音处理器和音频处理器之间实现无缝可靠的切换。下图是EVS编解码器的框图:
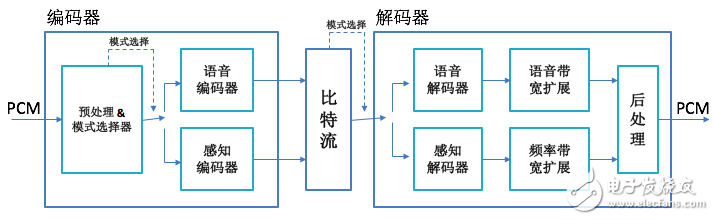
编码时先对输入的PCM信号做预处理,同时确定是语音信号还是音频信号。如是语音信号就用语音编码器编码得到比特流,如是音频信号就用感知编码器进行编码得到比特流。解码时根据比特流中的信息确定是语音信号还是音频信号,如是语音信号就用语音解码器解码得到PCM数据,然后做语音带宽扩展。如是音频信号就用感知解码器解码得到PCM数据,然后做频率带宽扩展。最后再做后处理作为EVS解码器的输出。
下面说说EVS的各个关键特性。
1,EVS支持全频段(8kHZ--48kHZ),码率范围是5.9kbps至128kbps。每帧是20Ms时长。下图是音频带宽的分布:
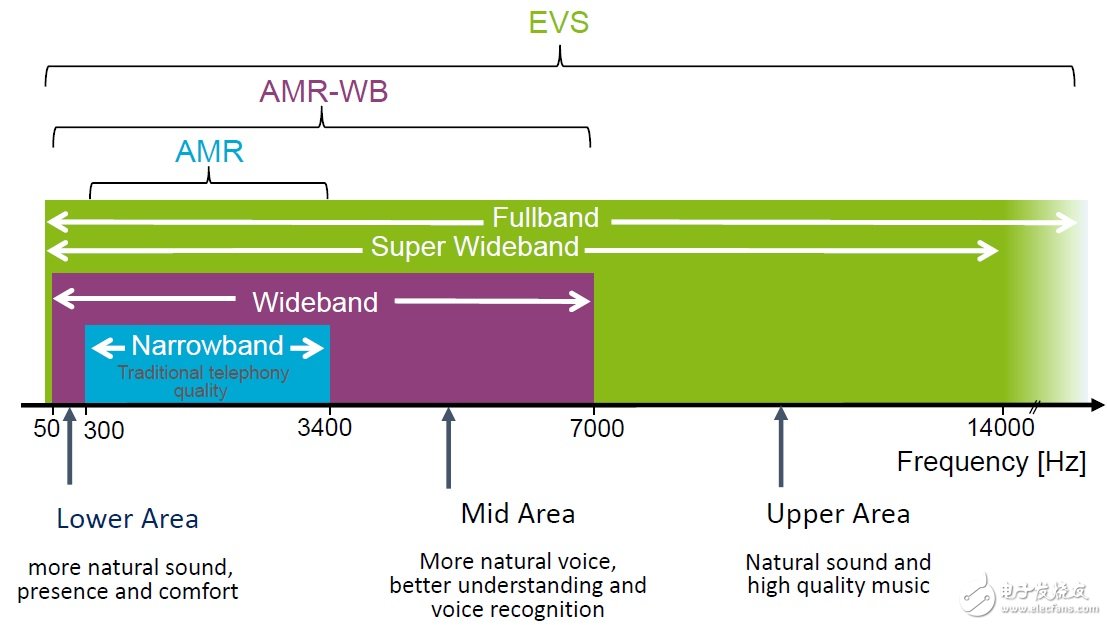
窄带(Narrow Band, NB)范围是300HZ-3400HZ,对应的采样率是8kHZ,AMR-NB用的就是这种采样率。宽带(Wide Band, WB)范围是50HZ-7000HZ,对应的采样率是16kHZ,AMR-WB用的就是这种采样率。超宽带(Super Wide Band, SWB)范围是20HZ-14000HZ,对应的采样率是32kHZ。全带(Full Band, FB)范围是20HZ-2000HZ,对应的采样率是48kHZ。EVS支持全频段,所以它支持四种采样率:8kHZ、16kHZ、32kHZ和48kHZ。
下图是在各种采样率下支持的码率:
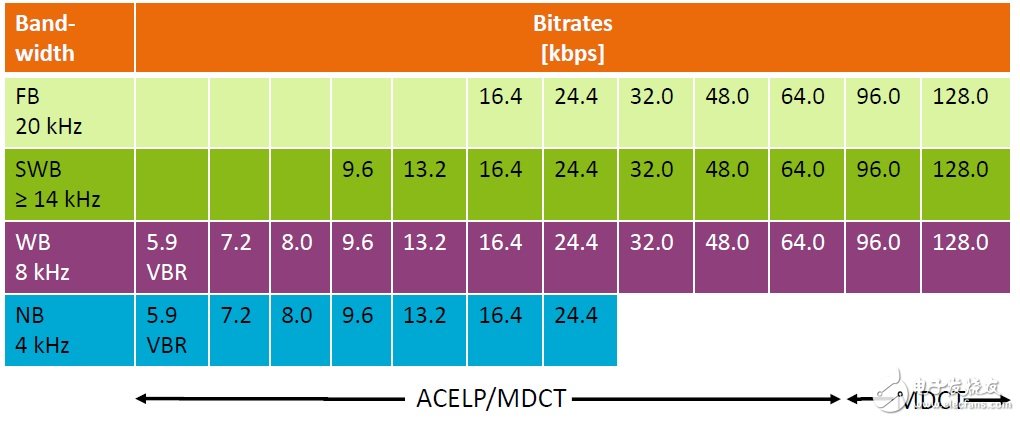
从上图看出只有在WB下支持全码率,其他采样率下只支持部分码率。需要注意的是EVS向前兼容AMR-WB,所以它也支持AMR-WB的所有码率。
2,EVS支持DTX/VAD/CNG/SID,这同AMR-WB一样。在通话过程中通常有一半左右时间讲话,其余时间处于聆听状态。在聆听状态时没必要发语音包给对方,于是就有了DTX(非连续传输)。要用VAD(静音检测)算法去判断是语音还是静音,是语音包时就发语音包,是静音时就发静音包(SID包)。对方收到SID包后就去用CNG(舒适噪声生成)算法去生成舒适噪声。EVS中有两种CNG算法:基于线性预测的CNG(linear prediction-domain based CNG)和基于频域的CNG(frequency-domain based CNG)。在SID包的发送机制上EVS跟AMR-WB不同,在AMR-WB中VAD检测到是静音时就发送一个SID包,然后40Ms后发送第二个SID包,随后每隔160Ms发送一个SID包,不过VAD一检测到是语音就立刻发送语音包。EVS中SID包的发送机制可配,可以固定每隔一段时间(几帧,范围是3--100)发送一个SID包,也可以根据SNR自适应的发送SID包,发送周期范围是8—50帧。EVS SID包的payload大小也与AMR-WB不同,AMR-WB的是40个字节(50*40=2000bps),EVS是48个字节(50*48=2400bps)。从上可以看出DTX有两个好处,一是可以节省带宽,增加容量,二是因为不编解码减少了运算量,从而降低功耗增加续航时长。
3,EVS也支持PLC(丢包补偿),这也同AMR-WB一样。不过EVS把Jitter Buffer Module(JBM)也包含了进来,这在以前的codec中是从来没有过的。我在使用中没有用到JBM,由于时间比较紧,也就没有时间去研究。后面有时间了定要好好研究一下,JB可是语音通信的难点之一同时也是语音质量的瓶颈之一呀。
EVS的算法时延根据采样率不同而不同。当采样率为WB/SWB/FB时总时延为32ms,包括一帧20ms的时延,编码侧输入重采样的0.9375ms时延以及8.75ms的前向时延,解码侧时域带宽扩展的2.3125ms时延。当采样率为NB时总时延减小为30.9375ms,相对WB/SWB/FB减小了1.0625ms, 这1.0625ms主要是在解码侧减少的。
EVS的语音质量(MOS值)相对于AMR-NB/AMR-WB有了明显的提升。下图是这几种codec的MOS值比较:
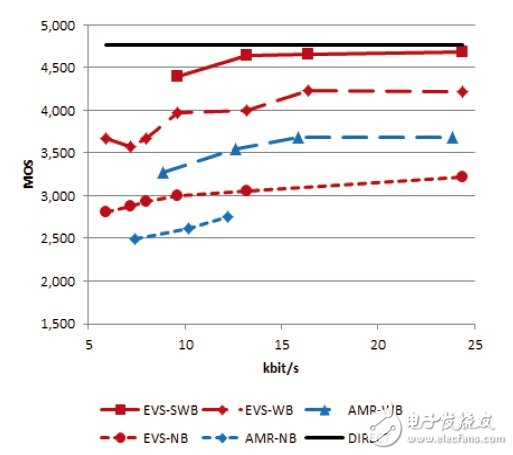
从上图看出,当采样率为NB时在各种码率下EVS-NB的MOS值比AMR-NB的MOS值显著提升;当采样率为WB时在各种码率下EVS-WB的MOS值同样比AMR-WB的MOS值显著提升;当采样率为SWB并且码率大于15kbps时EVS-SWB的MOS值接近了不编码的PCM的MOS值。可见EVS的语音质量是相当不错的。
用好EVS要做的工作在不同的平台上会有所不同,我是用在手机平台audio DSP上,用于语音通信。下面就说说为了手机支持EVS我做了哪些工作。
1,学习EVS相关的SPEC。要把前面我列的SPEC都看一遍,因为不是做算法,算法相关的可以看的粗,但是对特性描述相关的一定要看的细,这关系到后面的使用。
2,在PC上生成encoder/decoder的应用程序。我是在Ubuntu上做的,把PCM文件作为encoder的输入,根据不同的配置生成相应的码流文件,再把码流文件作为decoder的输入,解码还原成PCM文件。如果解码后的PCM文件听下来跟原始PCM文件无异样,说明算法实现是可信的(权威组织出来的算法实现都是可信的,如果有异样说明应用程序没做好)。做应用程序是为了后面的优化,也方便理解外围实现,如怎么把编码后的值变成码流。编码后的值放在indices(最多有1953个indices)中, 每个indices有两个成员变量,一个是nb_bits,表示这个indices有多少位,另一个是value,表示这个indices的值。Indices有两种存储方式:G192(ITU-T G.192)和MIME(MulTIpurpose Internet Mail Extensions)。先看G192,每一帧的G192的存储格式见下图:
第一个Word是同步值,分good frame(值为0x6B21)和bad frame(值为0x6B20)两种,第二个Word是长度,后面是每个值(1用0x0081表示, 0用0x007F表示)。Indices里的value用二进制表示,位上的值为1就存为0x0081,为0 就存为0x007F。下图是一个例子,采样率为16000HZ, 码率为8000bps,因此一帧有160位(160 = 8000/50),保存成G192格式就是160个Word。下图中头是0x6B21, 表示good frame,length是0x00A0, 后面160个Word是内容。
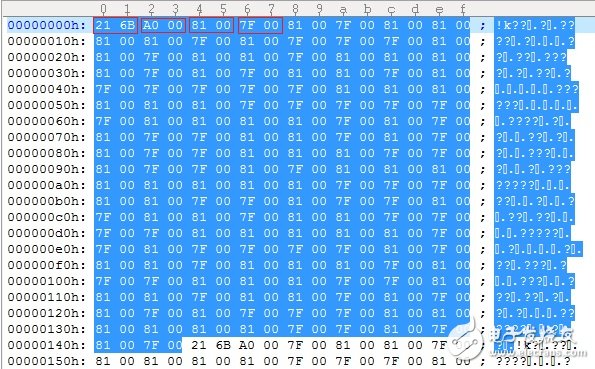
再来看MIME格式。要把indices的value值pack成serial值,具体怎么pack,见pack_bit()函数。MIME的格式是第一个Word是header(低4位表示码率index, 在用WB_IO时第5和6位要置1,EVS 时不需要),后面是比特流。还是上面采样率为16000HZ码率为8000bps的例子,但存成MIME格式,一帧有160位,需要20byte(20 = 160/8),如下图:
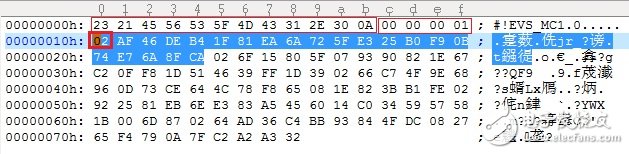
上图中头16个字节是reference code自带的,第17个字节是header,0x2表示以EVS 编码,码率是8kbps(8kbps index为2),后面的20个字节表示pack后的payload。
在语音通信中,要把indices的value值pack成serial值,然后作为payload发送给对方。对方收到后先unpack再解码得到PCM值。
3,原始reference code通常是不能直接使用的,需要优化。至于怎么优化,请看我前面写过的一篇文章(音频的编解码及其优化方法和经验),文章写的是比较通用的方法。我现在要在DSP上用,DSP的频率较低,只有三百多MHZ,不用汇编优化时搞不定的。我之前没用过DSP汇编,要在短时间内优化的很好有很大难度。老板权衡后决定用DSP IP厂商提供的优化好的库,汇编方面它们更专业一点。
4,对reference code的应用程序改造,方便后面调试验证时当工具使用。原始reference code保存成文件时是以字节为单位的,而DSP是以Word(两个字节)为单位,所以要对reference code里的pack/unpack函数改造,以适应DSP。
5,要想打电话时codec是EVS,Audio DSP 和CP上都要加相应的代码,先写各自的代码自调,然后联调。我自调时用AMR-WB的壳(因为EVS和AMR-WB的一帧都是20ms时长),即流程上用AMR-WB的,但codec从AMR-WB换成EVS。主要验证encoder、pack、unpack、decoder是否ok,其中encoder和pack是上行的,unpack和decoder是下行的。它们的先后关系如下图:
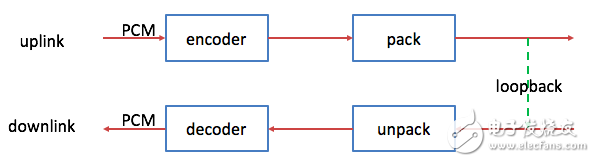
先调上行,把encode后的保存成G192格式,用decoder工具解码成PCM数据用CoolEdit听,跟自己说的话是一样的,说明encoder是OK的。再调pack,把pack后的码流保存成MIME格式,同样用decoder工具解码成PCM数据用CoolEdit听,跟自己说的话是一样的,说明pack是OK的。再调下行。由于CP还没有正确的EVS码流发给Audio DSP,就用loopback的方式来调试,具体是把pack后的码流作为unpack的输入,unpack后得到的保存成G192格式,用decoder工具解码成PCM数据用CoolEdit听,跟自己说的话是一样的,说明unapck是OK的。最后调decoder,把decoder后的PCM数据用CoolEdit听,跟自己说的话是一样的,说明decoder是OK的。这样自调就结束了。
6,与CP联调。由于前面自调时各关键模块都是调好的,联调起来相对比较顺利,没几天就调好了。这样打电话时就能享受EVS带来的高音质了。
技术专区
- 数据采集与监视控制系统相关技术
- 为何说计算机视觉已经成为新时代风向标
- 关于嵌入式听力诊断系统中如何伪迹消除
- 一款基于嵌入式视频服务器的远程实时视频采集系统实现流程详
- 关于嵌入式系统的分类与特点




