



为什么添加多个处理单元和内存后会引发那么多问题。
单颗芯片或一个封装内集成了各种各样的处理器和本地内存,使得对这些器件的测试和验证变得愈加困难,并且无法充满信心地签核它们。
除了传统的时序和时钟域交叉问题之外,在AI、机器学习或深度学习类等新型复杂芯片中还有一些越来越难以处理的问题。这类器件可以训练应用于特定用例的数据,从而学习独特的行为模式。在汽车或物联网等设计中的一些芯片还包括在线升级功能。
“异构计算在很多地方都有应用,包括人工智能、机器学习、5G、传感器融合和高性能计算,”OneSpin Solutions总裁兼首席执行官Raik Brinkmann说。 “现在可以通过云的方式把新的算法映射到硬件中。但是,如果不解决延迟、性能和功耗问题,云计算的应用也会受限。除了功能安全性之外,您还会遇到IC完整性问题。所以,当前最大的问题是如何在设计流程中解决所有这些问题。您是在某个可编程结构上实现它还是使用异构平台实现它?当您验证自己的设计目标时,是进行自下而上的指标分析,还是采用自上而下的方法?能不能保证足够的代码覆盖率。”

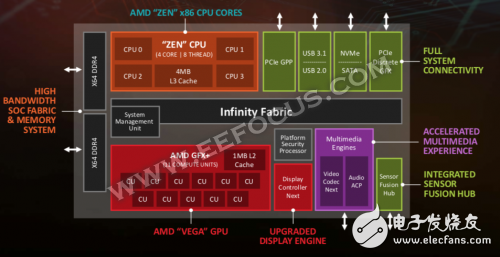
AMD异构架构
所有这些变化都带来了一系列新的挑战。验证和测试对象不再是单个计算组件和内存,而是开始包含越来越多的可编程硬件、不具备可编程能力的硬件、固件以及影响面覆盖从安全性到控制逻辑在内的所有指标的复杂软件栈。
“我们以前从来没有见过这么大规模的异构设计,”Cadence营销总监Adam Sherer说。“你的计算环境本身就是异构的,分析对象又是异构设计。现在你需要应对各种不同内存、人工智能和机器学习参数、包括传统IP在内的大量IP系列、拥有全新特征的多个处理器。使用UVM测试模式进行直接模拟的方法不再奏效了。”
有时需要使用不同的工具,但是真正的挑战却在于方法和流程,以及为了实现充分覆盖需要花费多少时间和精力。
“我们发现,目前的测试方案正在向严格定义了区间的系统级测试转变,”Sherer说。 “问题在于你无法真正复现现实世界的环境。还有一种替代方法是,通过压缩测试功能,降低测试规模,以保证可以在限定的时间窗口内完成这些测试。”
因为很多芯片只是作为更大系统的一部分运行,所以它们之间还存在接口相关的问题。
不同的架构
为了处理各种特定类型的数据,芯片中集成了各类加速器和内存,使得加快验证过程变得愈发艰难了。在面向数据中心训练、人工智能、机器学习和深度学习等应用的芯片中,这种集成各种加速器和内存的方法变得越来越普遍,同时,该方法也逐渐渗透到汽车等安全关键市场以及数据中心和边缘计算中使用的各种芯片的设计上。
这些芯片可能非常庞大而且复杂,还可能存在重大的延迟问题。验证过程需要尽可能早开始,因为随着设计流程的进行,工程师需要识别越来越多潜在的交互,使用一些可能并不十分熟悉的模型。
Marvell服务器处理器业务部门副总裁Gopal Hegde表示:“过去我们设计芯片时,总是把它划分成CPU内核和内存子系统。这些都是标准组件,我们总是关注必须支持哪些接口这类问题。但是现在地址空间大得多了,如何设计流水线,信号路径通过外部结构时对延迟有哪些影响都在考虑之列了。”
片外加速器和存储器有多种互连标准,但是很难同时支持所有这些标准。
“业界需要在标准化的接口上实现更好的数据流动,”Hegde说。 “我们有Gen-Z和CCIX(加速器的缓存一致性接口),我们真的很想只支持一个统一的接口,但是现在还有Gen5 PCIe,接口的统一显然很难实现了。”
还有一些报道点出了其它类似的挑战。“我们正在推出7nm芯片,”eSilicon营销副总裁Mike Gianfagna表示。“我们主要的关注层面是互操作性、系统级别的验证、IP的特点以及芯片在不同电压水平上的特性。”
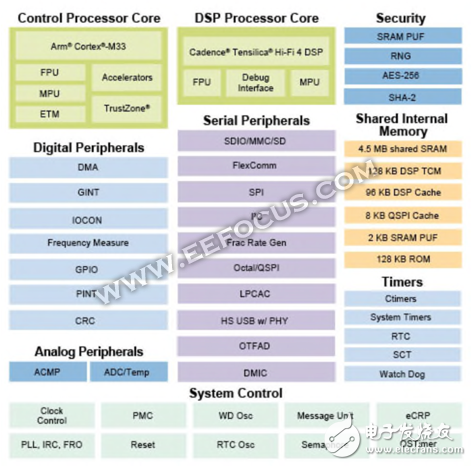
恩智浦异构架构
为了解决这个问题,eSilicon为AI、网络通信和交换开发了IP“平台”。“这是一组我们知道可以协同工作的IP,”Gianfagna说。 “我们还针对金属栈层开发了相应平台,以确保器件的可测试性、工作电压范围和可靠性。所有IP都可以使用相同的金属栈层,添加的所有第三方IP也可以使用金属栈层平台。通过这种方式,可以解决互操作性问题。我们认为这是未来的发展方向,您肯定需要可以和其它所有要素互操作的最佳IP。”




